
The Ultimate Guide to WordPress Website Health: Importance of Ongoing Monitoring for Site Owners
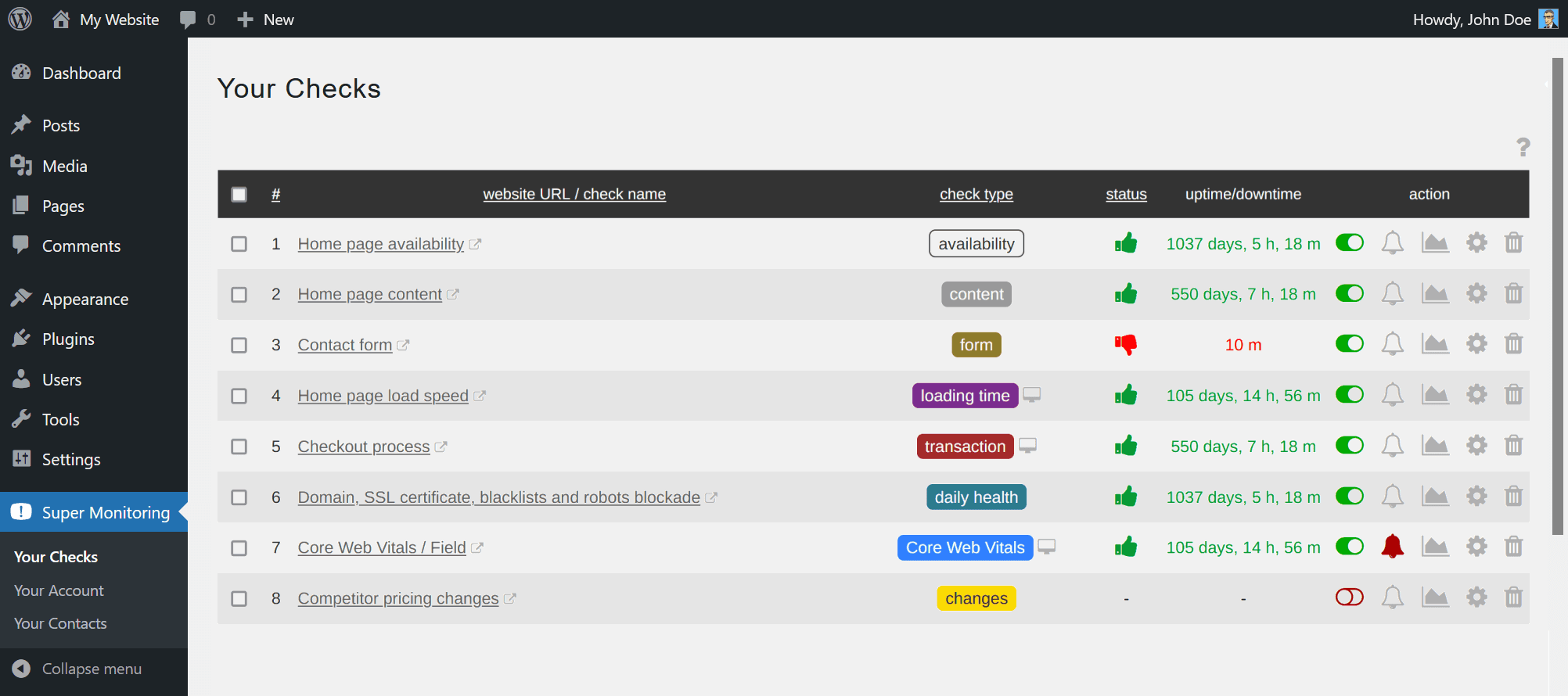
Here is the polished, publication-ready version of your article. All placeholder text has been removed, and the content has been refined for clarity, flow, and professional presentation while preserving the original structure and Markdown formatting.
—
How Ongoing Monitoring Keeps WordPress Websites Healthy: The Essential Guide for Site Owners
Keeping a WordPress site healthy isn’t a one-time task — it’s an ongoing commitment. Regular monitoring prevents downtime, reduces security risks, improves performance, and protects your brand reputation. This guide explains why continuous monitoring matters, which metrics to track, the best tools and processes, and how to build a monitoring strategy that delivers measurable results.
Introduction: Why Ongoing Monitoring Is Non-Negotiable
Every minute your WordPress site is slow, vulnerable, or down, you lose traffic, conversions, and credibility. Modern websites operate in a fast-moving environment: plugin updates, third-party integrations, evolving security threats, traffic spikes, and changing SEO expectations. While many site owners focus on design and content, they overlook the daily discipline that keeps a site functioning reliably. Ongoing monitoring fills that gap.
In this article you’ll learn exactly what continuous monitoring is, the key metrics and signals that indicate health or trouble, the best tools and configurations for WordPress sites, and practical workflows to implement immediately. You’ll also find real-world examples, a sample monitoring checklist, and conversion-focused calls to action to help you protect traffic and grow conversions. By the end, you’ll understand how proactive monitoring saves time and money, prevents crises, and provides the visibility needed to keep a WordPress site healthy and high-performing.
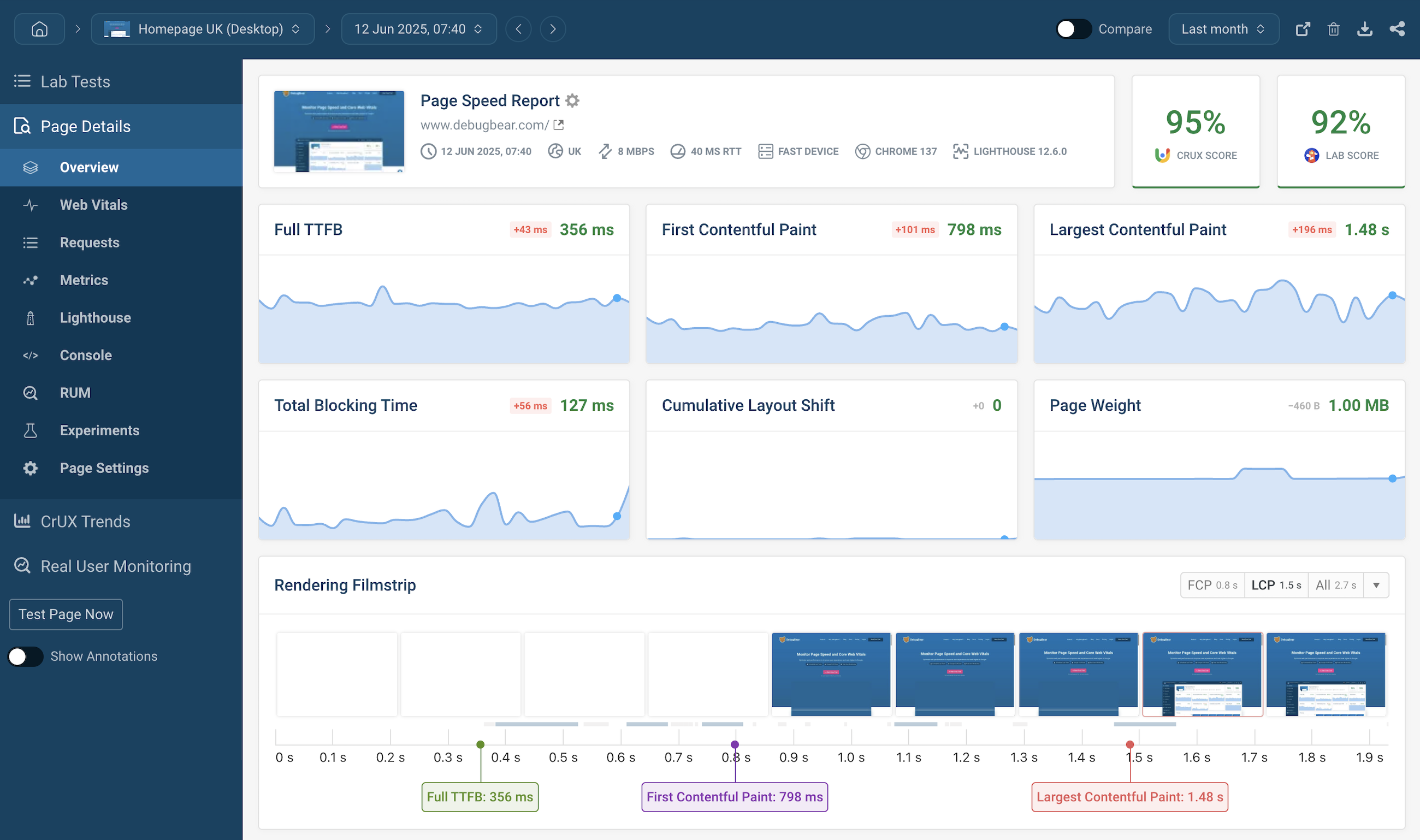
What Is Ongoing Monitoring for WordPress?
Ongoing monitoring is the continuous tracking of a website’s technical, performance, security, and user-experience metrics. Unlike periodic audits, it provides real-time or near-real-time signals so you can detect and resolve issues before they escalate.
- Proactive vs. reactive: Monitoring enables proactive fixes instead of chasing problems after they impact users.
- Scope: Includes uptime, speed, security, SEO signals, errors, resource usage, backups, and user behavior.
- Automation: Alerts, dashboards, and automated remediation reduce manual labor and human error.
- Downtime detection and automatic alerts mean faster restorations.
- Studies show each minute of downtime can cost businesses thousands; monitoring reduces mean time to detect (MTTD) and mean time to repair (MTTR).
- Detect malware, unauthorized changes, and suspicious logins quickly.
- Keep plugins and core up to date and spot risky changes introduced by updates or third-party code.
- Page speed and uptime are ranking signals — monitoring helps maintain performance consistently.
- User experience improvements lead to higher engagement and conversion rates.
- Backups and integrity checks ensure restore capability after failures or attacks.
- Monitoring verifies backups run successfully and are restorable.
- Early detection of PHP warnings, deprecated function calls, and plugin conflicts reduces the effort required to remediate.
- Smaller, timely fixes are less costly than major recovery work.
- Pingdom — simple uptime checks, alerts, and basic performance insights
- UptimeRobot — cost-effective multi-location checks and alerting
- Site24x7 — advanced synthetic transactions for e-commerce flows
- New Relic — deep application performance monitoring (APM) and WordPress plugin support
- Google Analytics (with Core Web Vitals reporting) — RUM for user experience
- WebPageTest & GTmetrix — lab-based performance audits and recommendations
- Wordfence or Sucuri — WordPress-focused malware scanning and firewall
- MalCare — automated cleanup plus monitoring alerts
- Cloudflare — WAF, DDoS protection, and analytics
- Sentry — captures PHP and JavaScript errors and provides actionable stack traces
- Loggly / Papertrail — centralized log aggregation and search
- Elastic Stack (ELK) — advanced log analytics for high-volume sites
- UpdraftPlus / BlogVault — managed backups with restore verification
- ManageWP — scheduled backups and monitoring in one dashboard
- Ahrefs / SEMrush — track SEO health, crawl errors, and broken links
- Google Search Console — detect indexing issues and security alerts
- Decide acceptable uptime, performance, and recovery time objectives (RTO/RPO).
- Example: 99.9% uptime, RTO = 1 hour, RPO = 1 day.
- Record normal ranges for CPU, response times, and error rates for comparison.
- Baselines help identify anomalies that matter instead of chasing noise.
- Combine at least one uptime checker, one APM/RUM tool, a security scanner, and error tracking.
- Integrate alerts into Slack, email, or ticketing systems for visibility.
- Create actionable alerts (e.g., “alert when 5xx rate > 0.5% for 5 minutes”).
- Define escalation: first responder, backup responder, and leadership notifications.
- Automated cache purges, service restarts, or plugin rollback scripts can fix transient issues quickly.
- Use scripts carefully and test in staging to avoid causing outages.
- Weekly check-ins for alerts, monthly performance reviews, and quarterly security scans.
- Document recurring issues and update action plans.
- Receive alert from uptime monitor (e.g., Pingdom).
- Confirm downtime via secondary tool or from a different location.
- Check server health: CPU, memory, disk, and database connections.
- Restart web server / PHP-FPM if a resource spike is detected.
- If unresolved, enable maintenance page, notify stakeholders, and escalate to host or developer.
- Post-incident: perform root cause analysis and implement steps to prevent recurrence.
- Alert triggers for high TTFB or LCP.
- Check recent deployments, plugin updates, and error logs.
- Validate caching layers (CDN, server cache) and purge as needed.
- Use APM to identify slow database queries or external API calls.
- Apply quick fixes: restore a known-good plugin or optimize a query; plan a permanent fix.
- Isolate the site: enable maintenance mode, block suspicious IPs at the firewall.
- Scan with Wordfence/Sucuri and collect forensic logs.
- Restore from a clean backup if compromise is confirmed, then apply patches and rotate credentials.
- Submit to Google for review if malware impacted search listings.
- Check uptime and critical alerts.
- Review any failed backups and retry immediately.
- Scan for new malware or high failed login activity.
- Review error logs and resolve recurring PHP/JS errors.
- Examine Core Web Vitals and spot trends.
- Verify plugin and theme updates in staging before production deployment.
- Test a full restore from backups on a staging environment.
- Conduct a security audit and review user accounts/permissions.
- Analyze traffic and conversion trends; adjust thresholds and alerts accordingly.
- Too many noisy alerts: Create composite alerts and suppress non-actionable noise. Tune thresholds based on baselines.
- Relying on a single tool: Combine uptime checks, RUM, and server-side APM for full visibility.
- Not testing backups: Backups are only useful if verified — schedule periodic restore tests.
- No escalation process: Without a formal path, small issues become major incidents. Define roles and time-based escalations.
- Ignoring logs: Logs are a goldmine for diagnosing problems; aggregate and analyze them regularly.
- Use Google Search Console alerts to detect manual actions or security issues quickly.
- Monitor Core Web Vitals for priority pages and align optimization efforts with revenue impact.
- Alert on broken links or missing content that affect user journeys and SEO.
- WordPress Maintenance Services — anchor: “managed maintenance”
- WordPress Security Best Practices — anchor: “security best practices”
- Case Studies — anchor: “real-world results”
- Hero image: Dashboard view of monitoring graphs — alt text: “WordPress site monitoring dashboard showing uptime and performance metrics.”
- Diagram: Monitoring workflow — alt text: “Monitoring workflow diagram: detect, alert

Why Ongoing Monitoring Matters: Concrete Benefits
Monitoring isn’t just a technical checkbox — it directly impacts revenue, trust, and growth. Here’s how:
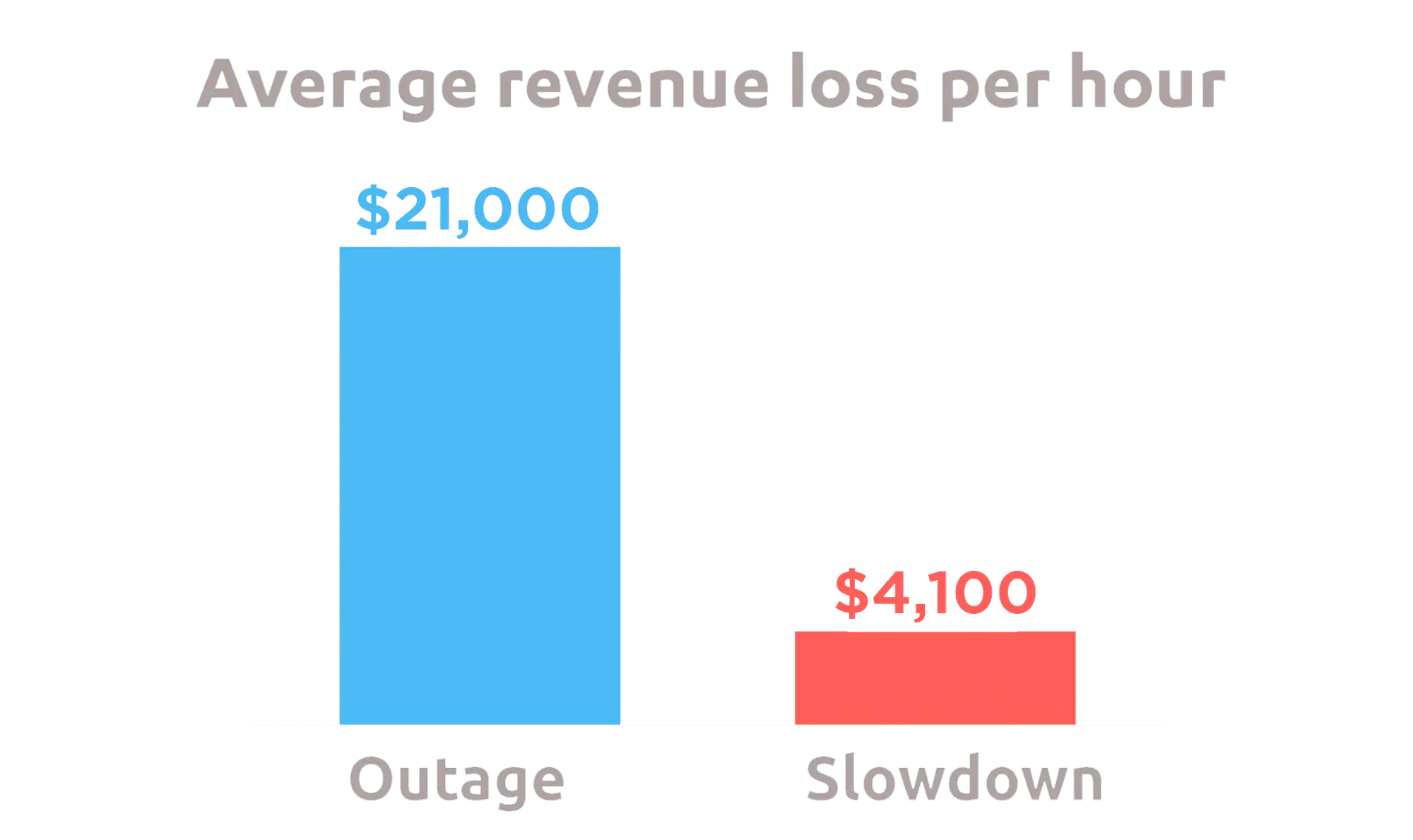
1. Minimize Downtime and Revenue Loss

2. Strengthen Security and Reduce Breach Risk
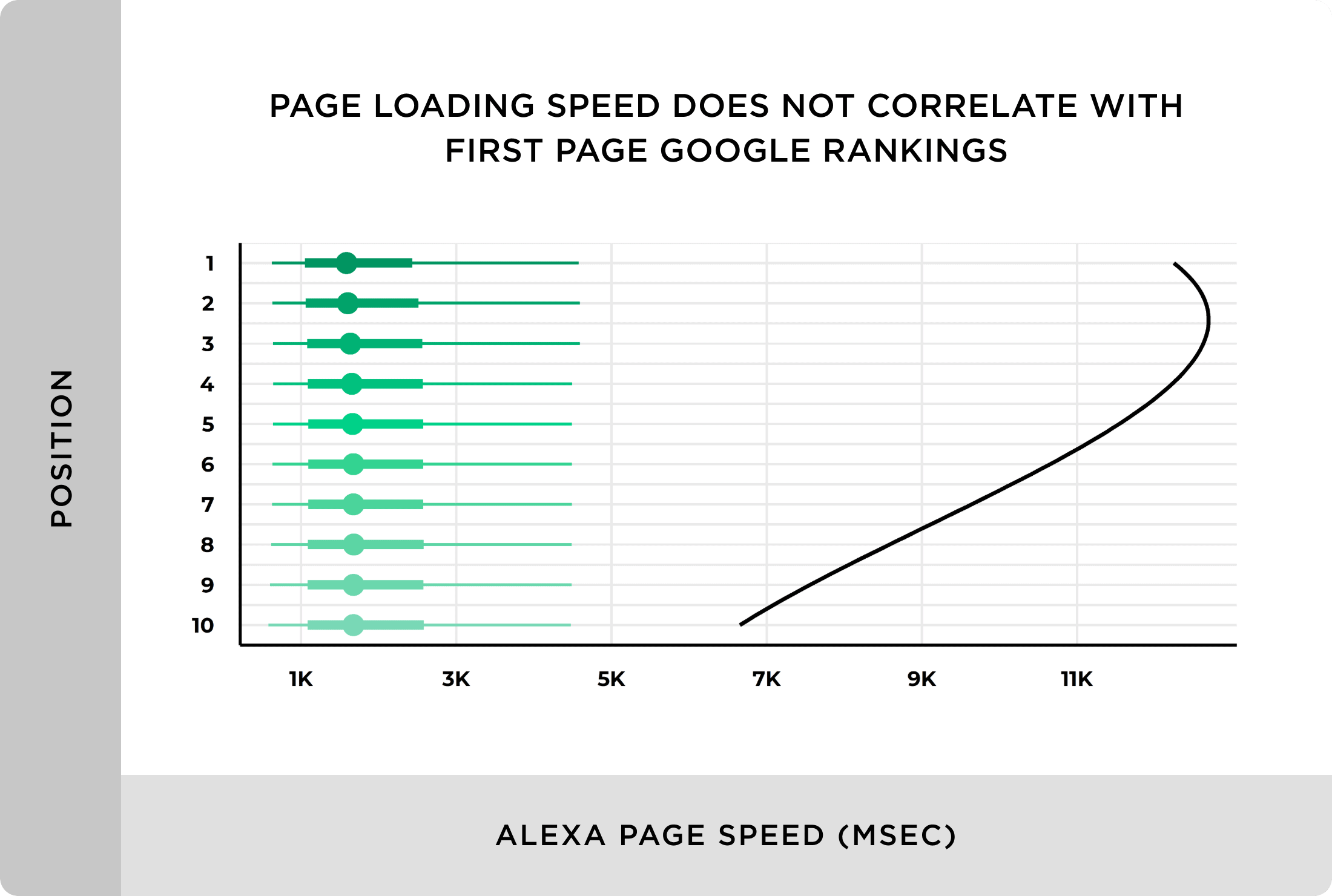
3. Improve Performance and SEO

4. Ensure Data Integrity and Availability
5. Reduce Technical Debt and Maintenance Costs
Key Metrics to Monitor for a Healthy WordPress Site
A robust monitoring program tracks multiple categories of indicators. Below are the essential signals, why they matter, and recommended thresholds.
| Category | Metric / Signal | Why It Matters | Suggested Threshold |
|---|---|---|---|
| Availability | Uptime | Site accessibility and reliability | 99.9%+ |
| Performance | Time to First Byte (TTFB), Largest Contentful Paint (LCP), First Contentful Paint (FCP) | Core Web Vitals and user experience | LCP < 2.5s, TTFB < 500ms |
| Security | Malware scans, file integrity changes, failed login attempts | Detect compromise and unauthorized changes | Zero unexplained changes; alert on >10 failed logins/min |
| Error Monitoring | HTTP 5xx/4xx rates, PHP errors, database errors | Application health and broken functionality | 4xx < 5% of responses; 5xx < 0.1% |
| Capacity | CPU, memory, disk I/O, database connections | Prevent resource exhaustion and slowdowns | Baseline-dependent; alert when >75% utilization |
| Backups | Backup success/failure, restore verification | Recovery readiness | Daily backups with successful restores tested monthly |
| User Behavior | Conversion rates, bounce rate, session duration | Business impact indicators | Baseline-dependent; detect sudden drops |
Best Tools for Ongoing WordPress Monitoring
Choose tools that integrate with WordPress, provide alerting channels you use (email, Slack, SMS), and support automation. Here are recommended categories and specific tools used by professionals.
Uptime & Synthetic Monitoring
Performance & Real User Monitoring (RUM)
Security Monitoring
Error Tracking & Logs
Backup & Integrity Tools
Site Audit & SEO Monitoring
How to Build an Effective Monitoring Strategy
Monitoring is most effective when it’s planned, prioritized, and integrated into workflows. Follow these steps to create a practical program.
1. Define Objectives and SLAs
2. Establish Baselines
3. Select Tools and Integrations
4. Implement Alerting Rules and Escalation Paths
5. Automate Common Remediations
6. Schedule Regular Reviews
Practical Monitoring Workflows and Playbooks
Having documented steps saves precious minutes during incidents. Below are concise playbooks for common scenarios.
Playbook: Uptime Incident (Site Down)
Playbook: Performance Degradation
Playbook: Security Alert / Malware
Case Studies: Real-World Gains from Ongoing Monitoring
Case Study 1: E-commerce Site Reduced Downtime by 85%
An online retailer used synthetic monitoring and APM to reduce average downtime from 4 hours per month to 36 minutes per month. Rapid alerts and an automated rollback script for plugin updates cut MTTR from 90 minutes to 10 minutes, preserving sales during peak times.
Case Study 2: SaaS Landing Page Improved Conversions by 22%
A SaaS company discovered slow page loads were harming conversions. After implementing RUM and WebPageTest monitoring, they focused on LCP and reduced page load time from 4.2 seconds to 1.8 seconds. The increased conversion rate lifted revenue without changing traffic volume.
Case Study 3: Small Business Prevented Malware Spread
A local clinic’s site was flagged by Google for malware. Because backups were monitored and tested, the team restored a clean version within 2 hours, submitted a Google review request, and had search visibility restored in days instead of weeks.
Checklist: Daily, Weekly, and Monthly Monitoring Tasks
Use this checklist to operationalize ongoing monitoring for WordPress.
Daily
Weekly
Monthly
Common Monitoring Mistakes and How to Avoid Them
Integrating Monitoring with SEO and Content Strategy
Monitoring isn’t just technical — it supports your SEO and content performance goals. Track indexing issues, crawl errors, and page speed for high-value landing pages. Alert on sudden traffic drops or ranking changes and tie them to technical or content causes.
Internal and External Link Recommendations (SEO-Ready)
Internal linking improves crawlability and user navigation. Suggested internal links to include from this article:
Authoritative external links to improve credibility:
Image Suggestions and Alt Text for Accessibility
about the author
Making sure your website stands out in the Great North.